[2026-05-14] Towards a Reliable Intrusion Detection Benchmark Dataset
🦥 본문
Motivation
최근 네트워크 규모가 기하급수적으로 커짐에 따라, 침입 활동으로부터 주요 네트워크를 보호하기 위한 침입 탐지 시스템(IDS)의 중요성이 그 어느 때보다 커짐. 배포하기 전에 상당한 양의 테스트, 평가 및 튜닝이 필요한데, 연구자들은 일반적으로 종종 최적이 아닌 데이터셋에 의존
- 유효한 데이터셋 확보의 어려움: 제안된 기법을 테스트하고 평가하기 위한 포괄적이고 유효한 데이터셋을 찾는 것이 어려움
- 개인 정보 및 공유 문제: 많은 고품질 데이터셋이 개인 정보 보호 문제로 인해 공개되지 못함
- 익명화 및 다양성 부족: 공유 가능한 데이터셋들도 과도한 익명화로 인해 현재의 트래픽 추세를 반영하지 못하며, 트래픽과 공격 시나리오의 다양성이 매우 부족
- 주기적 업데이트의 필요성: 공격 기법은 끊임없이 진화하므로, 벤치마크 데이터셋 역시 최신 트렌드를 반영하여 주기적으로 업데이트가 필요
기존 IDS 평가 방법 및 한계
- 공개 데이터셋 재현 : 공개된 실제 공격 트래픽을 replay하여 시스템을 평가
- 트래픽 생성 : 인위적으로 공격 및 정상 트래픽을 생성. 소프트웨어 생성기 (ex : Curl-loader)나 하드웨어 생성기 모두 실제 공격을 완벽히 모사하는 데 한계가 있음
- Testbed design : 실험 환경 구축
- 시뮬레이션 : 공격자, 피해자, 네트워크 장비 등을 소프트웨어(NS-2, Opnet 등)로 구현하는 방식
- 에뮬레이션 : 실제 기기를 공격자와 대상으로 사용하되, 네트워크 토폴로지만 소프트웨어로 재현하여 현실성을 높인 방식
- 직접적으로 재현 : 라우터, 스위치, 컴퓨터를 실제로 배치하여 토폴로지를 구축하는 가장 현실적인 방식
→ 객관적인 평가 기준을 세우고 이를 충족하는 새로운 데이터셋 생성 모델을 만들고자
Proposed Framework
기존 데이터셋 평가 방법 및 한계
데이터셋 평가 방법에 대한 연구 부족. 기준들이 파편화되어 있거나 실제 트래픽의 특징을 전부 담아내지 못함
- Scott : 중복성, 내재적 예측 불가능성, 복잡성 또는 다변수 종속성
- Heidemann & Papadopoulos : 개인정보 보호 및 익명화, 로컬 관찰 또는 로컬 추론과 같은 사용 불가능한 데이터 유형 , 새로운 기술 개발, 이동 표적 및 커버리지
- 데이터가 이미 존재하더라도 지속적인 관찰이 중요하다고 봄
- Nehinbe : 소유자 승인, 문서화 문제, 라벨링, 익명성 등 절차적/관리적 측면 강조
- Shiravi et al. : 현실적인 네트워크/트래픽, 라벨링된 데이터셋, 전체 상호작용 캡처, 공격의 다양성
평가 기준
- 완전한 네트워크 구성(Complete Network Configuration) : real world를 대표할 수 있도록 PC, 서버, 라우터, 방화벽 등 모든 장비를 갖춘 완벽한 네트워크 토폴로지가 기반
- 완전한 트래픽(Complete Traffic) : 소스에서 목적지로 가는 패킷 시퀀스가 현실적.
- realistic traffic
- pseudo-realistic traffic : 정상적인 데이터셋에 네트워크 공격을 주입
- synthetic(합성) traffic
- 라벨링된 데이터셋(Labeled Dataset) : 데이터셋의 신뢰성을 보장. 네트워크 데이터셋에서는 pcap을 netflow로 변환해야 flow에 대한 신뢰할 수 있는 라벨을 가질 수 있음.
- unlabeled, partially-labeled, fully-labeled로 존재
- 공격의 이름과 유형이 없고 정상/악성으로 구분되기도 함
- 완전한 상호작용(Complete Interaction) : 비정상 행위에 대해 가용한 정보의 양
- 모든 네트워크 상호작용을 포함해야 함
- 완전한 캡쳐 (Complete capture) : 모든 트래픽을 캡쳐
- 트래픽을 부분적으로 캡쳐하거나 기능이 없거나 라벨링되지 않은 트래픽을 제거하는 경우가 있는 데, 오탐율 계산에 차질이 생김
- 사용 가능한 프로토콜 : 트래픽 특성에 따라 프로토콜이 다름
- bursty traffic : 패턴이 불균일하고 몰리는 트래픽. HTTP와 FTP 프로토콜
- interactive traffic : end point 간에 짧은 요청과 응답 쌍으로 구성
- Latency sensitive traffic : 데이터가 정해진 시간에 정확히 배달되는 것이 중요한 트래픽. VoIP나 화상 회의 프로토콜
- Non-Real-time traffic : 뉴스나 메일 트래픽
- 공격 다양성 : 공격 유형은 업데이트 되기 때문에, 새로운 공격 및 위협 시나리오를 사용해야 함
- 익명성 : 개인정보 문제를 때문에 IP와 페이로드 제거
- DPI에서는 유용성이 감소됨.
- 이질성(Heterogeneity) : 다양한 출처의 데이터를 제공하여 완전한 테스트에사용
- 네트워크 트래픽
- OS 로그: 시스템 내부에서 발생하는 이벤트 기록
- 네트워크 장비 로그
- 자원 사용량
- Feature set : 다양한 출처에서 다양한 feature를 추출하여 테스트하고 분석할 수 있는 유용성을 제공
- Metadata : 네트워크 구성, 공격자 및 피해자의 OS, 공격 시나리오 등 정보를 문서화
수식
\[\sum_{i=1}^{n} W_i \left( \sum_{j=1}^{m} V_j * F_j \right)\]- W : 가중치
- 해당 논문에서는 공격과 프로토콜을 중요하게 생각하여 가장 높은 0.25로 둠
- V : 하위 요인의 계수. 경험이나 서로 다른 시나리오에서의 하위 요인 분포에 기반
- 예를 들면, HTTPS는 74%, HTTP 10% 등.
- F : 데이터셋에서 특정 요인 및 하위 요인의 출현 빈도.
- 해당 요소가 있으면 1, 없으면 0으로 할 수도 있고 다중값을 가질 수도 있음
- n : 특징의 수.
- 위의 11가지 주요 특징
- m : 각 요인의 계수 수
- 예를 들어, 프로토콜의 종류는 HTTP, FTP.. 로 5개. 공격 다양성 같은 경우도 DoS, DDoS.. 로 7개
- 대체로 1임.
- 기존 데이터셋 적용
- 가중치 : [0.05,0.05,0.1,0.05,0.05,0.25,0.25,0.05,0.05,0.05,0.05]
- 공격 분포 : Browser (36%), Bruteforce (19%), DoS (16%), Scan (3%), DNS (3%), Backdoor (3%), Others (20%).
- 프로토콜 분포 : http(10%), https (74%), ssh(2%), ftp(6%), email (1%), another(7%).
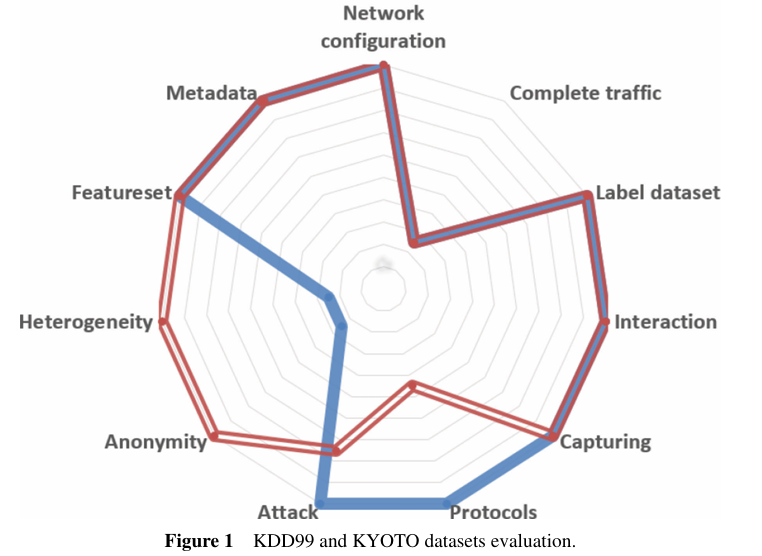
- KDD99 : 현대적 프로토콜의 부재로 0.56의 낮은 점수. 완벽한 트래픽은 가중치가 낮아서 없어도 0.05 밖에 안깎임
- KYOTO : 완벽한 트래픽, 익명성과 이질성 부분에서 미흡함
Generating Reliable Dataset
B-profile
인간의 상호작용의 추상적인 행동을 프로파일링하고 자연스러운 정상 배경 트래픽을 생성하는 역할
- 사용자가 생성하는 네트워크 이벤트를 머신러닝과 통계 분석 기법을 통해 캡슐화
- 추출 특징 : 프로토콜 별 패킷 크기 분포, 플로우 당 패킷 수, 페이로드 내 특정 패턴, 페이로드 크기, 프로토콜 요청 시간 분포
-
생성 단계
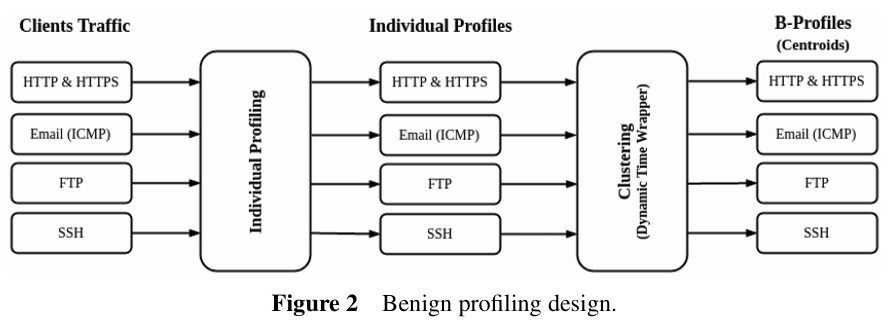
- 개별 프로파일링 : HTTP, HTTPS 등 프로토콜에 대한 사용자의 활동을 매일 30분 단위로 캡쳐 (48개의 bin)
- 캡쳐 방법 : MITM, 네트워크 스니핑, 브라우저 및 이메일 기록
- 클러스터링 : 개별 사용자 프로파일을 통해 다른 비슷한 분포를 가진 사용자들끼리 그룹화.
- X-Means 알고리즘을 사용하여 클러스터 개수를 자동으로 학습
- 클러스터링 시, 거리 함수는 DTW를 사용
- DTW : 시계열 데이터 간의 유사성을 측정하는 알고리즘.
- 클러스터 Centroid가 추상적 행위 모델이 됨
- 에이전트가 추상적 행위 모델 중 하나를 선택하여 인간 행동을 모방하며, 웹 크롤링 메커니즘을 통해 실제 트래픽을 발생
- 개별 프로파일링 : HTTP, HTTPS 등 프로토콜에 대한 사용자의 활동을 매일 30분 단위로 캡쳐 (48개의 bin)
M-profile
공격 시나리오를 설명하고 수행하는 데 사용.
- Infiltration from inside : 이메일을 통해 악성 문서를 전달, 취약한 문서 뷰어를 통해 백도어를 실행한 후 내부 네트워크를 스캔하고 추가 침투 시도
- 실패한 Infiltration from inside : 공격이 항상 성공하는 것이 아니기 때문에 권한 상승에 실패하거나 쿠키 탈취로 대신하는 시나리오
- DoS : HTTP DoS 툴을 사용하여 웹 서버의 소켓을 모두 점유
- Web application 공격 : SQL injection, command injection, unrestricted file upload
- Brute force : 서비스 계정을 탈취하기 위한 딕셔너리 공격
- 최신 취약점 공격 : Heartbleed, shellshock, Apple SSL 라이브러리 공격 포함
Evaluation
제안된 B-profile, M-profile 모델들은 11가지 기준을 만족함
- 완전한 네트워크 구성 : 게이트웨이, 라우터, 스위치, 서버 및 PC를 모두 포함하는 실제적인 네트워크 토폴로지를 구현
- 완전한 트래픽 : B-profile을 통해 배경 정상 트래픽을 생성하고 M-profile을 통해서 다양한 공격 시나리오를 실행하여 현실적인 데이터셋을 만듦
- 네트워크 상호작용 : 네트워크 토폴로지에 따라 완전한 정상 네트워크 상호작용 제공. M-profile의 경우 내부 및 외부 공격을 모두 고려하여 완전한 네트워크 상호작용을 제공
- 완전한 캡쳐
- 사용 가능한 프로토콜 : 현대 네트워크에서 필수적인 HTTP, HTTPS, SSH, FTP, SMTP, IMAP, POP3 프로토콜을 모두 포함
- 공격 다양성 : M-profile이 다양한 공격을 수행
- 이질성 : 트래픽 기록 뿐만 아니라 CPU 및 메모리 리소스 사용량 같은 시스템 로그를 수집
- 라벨링
- 날짜 기반 라벨링 : 정상 트래픽 있는 날과 특정 공격이 수행된 날로 분류
- 상세 공격 태깅 : 개별 flow에 대해 구체적인 공격 명칭을 태그
- Feature Set
- 네트워크 트래픽 feature : 프로토콜, 바이트 수, 패킷 수, 플로우 크기 등
- 자원 사용량 feature : 서비스 실행 속도, 프로세서 및 메모리 사용량, 서비스 오류율
- Metadata : 토폴로지(머신 수, 운영체제, 애플리케이션), 정상 활동(사용자 수, 활동 유형), 악성 활동(시뮬레이션된 침입, 공격 유형), 라벨링 방법, 추출된 특징 목록
개인적인 생각
- 배경 트래픽과 어떻게 구분을 했다는 건지 서술이 안됨
- B-profile이라는 게 결국은 합성 데이터라 pseudo-realistic 한 게 아닌가
- 자세하게 들어가서 B-Profile에서 X-means와 DTW를 사용하여 분석한 모델인데, 예측 불가능한 사용자 행동이나 복잡한 노이즈를 대변할 수 있나? → 너무 깨끗한 환경 아닌가?
- 후속 논문에서 라벨링 문제나 캡처 오류 같은 게 발견됐는 데 이 프레임워크가 신뢰할 수 있는 기준인가? → 즉, 설계 단계에서만 평가 가능하며, 그 평가마저 본인들의 주관임. 결과물인 데이터셋에 대해서는 신뢰 할 수 없음
- 결국은 최신 공격과 프로토콜은 계속 업데이트 될 예정이므로 데이터셋도 그에 맞춰 빠르게 업데이트 해야 한다.
Leave a comment